Filtering spectra or wavelengths is the means of ignoring wavelength “noise” and building your model on the more integral part of the spectrum. Within the spectrum of a data collection, there will be segments which show chaos and segments which show clear variance. Our goal when filtering is to exclude the chaotic and non-informative parts and focus on the area with clear variance.
This helps create better models that have:
- Less LVs (latent variables), resulting in models that are more robust.
- Smaller error and better performance parameters (R2, F1).
- Better error distribution (condensed around the black line).
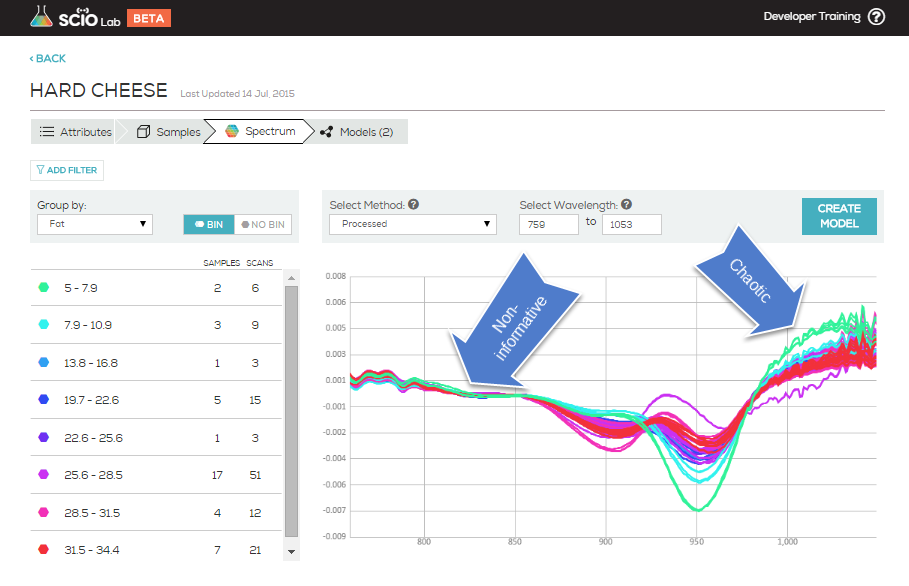
The following example, taken from the default Hard Cheese collection, Spectrum tab view, shows the entire wavelength of the data collection filtered by fat. You can see easily the areas that included too much chaos or too much non-informative data to be useful when creating a model.
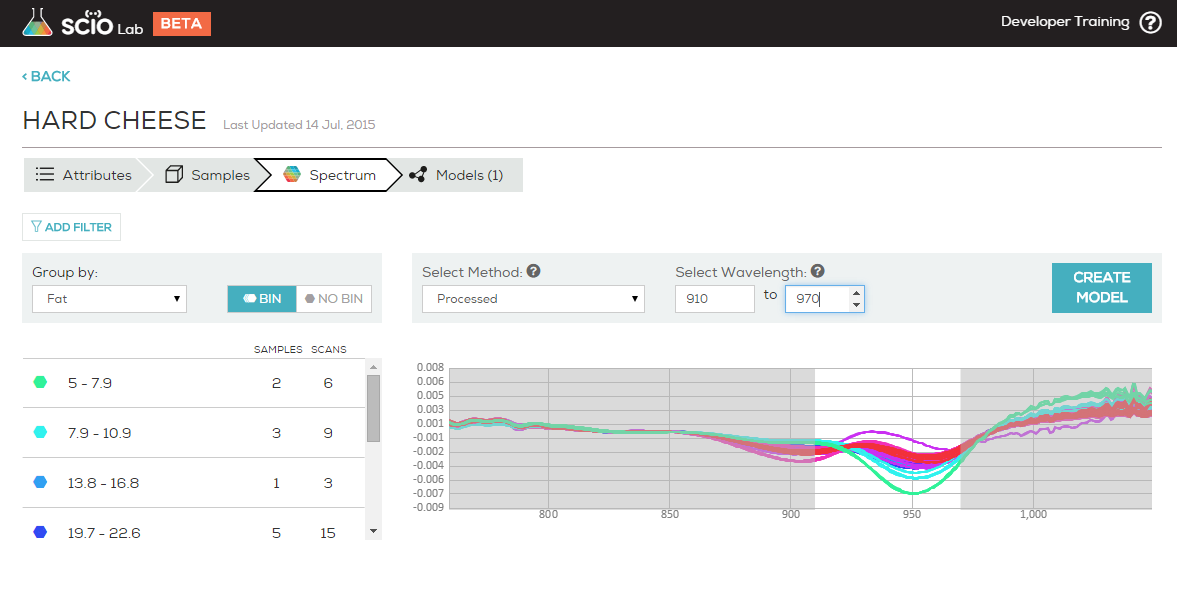
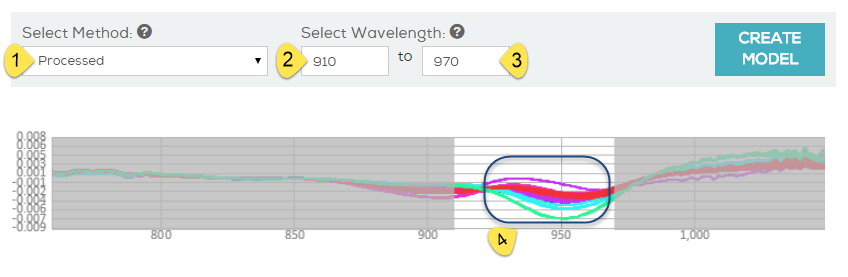
The second example shows the same collection filtered to a range of 910-970 and preprocessed using Processed.
Here, you can easily identify the clear, logical variance of the samples (low fat spectra at the top, high fat at the bottom) and the strength of the model this collection will build.
Tips:
- Removing noisy parts of the spectrum or focusing on ranges that look informative will typically improve your results significantly.
- Check a few different wavelength ranges when creating your models for best results.