Developer Terms and Conditions › The Development › Molecular Sensing Models › Trying to get a True/False element answer from a model.
- This topic has 21 replies, 12 voices, and was last updated 8 years, 10 months ago by
otto.kalliokoski@gmail.com.
-
AuthorPosts
-
November 11, 2015 at 11:28 pm #2354
rober@onirikmagazine.com
ParticipantI already read all the online guide several times and see all the online videos but it seems that Im missing something.
I made a model composed of a few pills that I have around (lets say calcium vitamin, ibuprofen and iron vitamin pills)
1) First I made a model , let say “My Pills”
2) I create one list attribute called “PillType” with 3 possible values (calcium, ibuprofen, iron)
3) I create another date attribute called “Scaned on”, so each sample will have a different date-time an will be unique.
4) I create a new sample and scan a calcium pill 3 times
5) I create a new sample and scan a Ibuprofen pill 3 times
6) I create a new sample and scan a Iron pill 3 times
I do step 4-6 until I get 40 samples.
7) Go to Spectrum and select “Group by” “PillType” and click on the “Create Model” button.
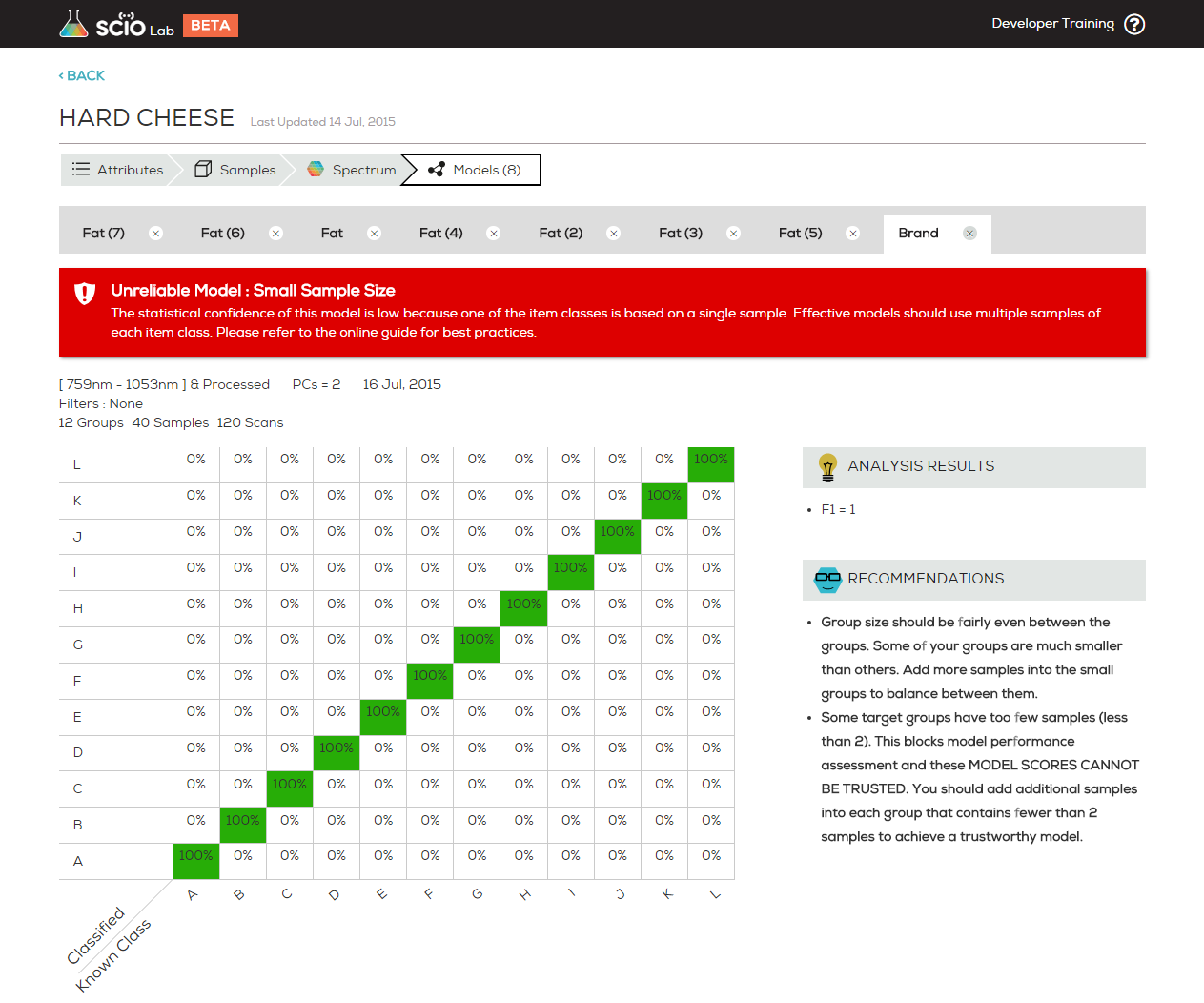
I get this kind of table https://dev.consumerphysics.com/wp-content/uploads/2015/05/Creating-models_bad-model.png
But without any red warning, the ANALYSIS RESULTS F1 = 0.941, and no recommendations.
When y try the model, and check it recognizes pretty well the 3 types of pills.
When I try another pill (vitamin C pill) that is not in the model, it still return any of the 3 pills in my model as a match.
Am I missing something conceptual here?, I want to start doing a simple binary check like, “is this pill viagra or is it not”, but the answer Im getting is like “from the 3 options you have on your model this is the closest match I can give you”.
Is there an option of % of confidence on the result?, is there a way to make a model to check a true/false answer given one element?
Thanks and sorry if this question is realy dumb!.
November 12, 2015 at 7:03 am #2355 rejsharpParticipant
rejsharpParticipantHi Rober – It is an excellent question, and not dumb at all.
I was thinking about the same issue with respect to Paul Brady’s currency project.
How can we get a response that shows the latest scan is significantly outside others in the same collection, i.e. an unknown.In case CP don’t spot your question, I will ask them directly by PM, and share the answer. (unless you have already done so?).
Note: When you make your real collection, each sample should come from a different batch of pills so that you do not unfairly tighten the range of scan results. But to test “seen before?” it is exactly right! (please forgive me if you already understood that).
November 12, 2015 at 10:06 am #2364ParticipantThanks rejsharp!!!, maybe if it shows the % of confidence in the match might do the trick (less than say 80% confidence can be taken as false).
Awesome your contribution on allmost all the post in the forum, kuddos!.
November 12, 2015 at 10:43 am #2369pfbrady@virginmedia.com
ParticipantAgreed on both points. How do I get an overall % confidence or even a % confidence per spectrum band. So overall might be low but in a specific spectrum band where my key differentiator is most active how can I get a % confidence for that band. At the demo we looked at %fat in cheese where a specific band gave the widest spectrum. A confidence level in this specific band would be different to an overall confidence level for the whole scan. Do I need to write an app to do this?……
November 13, 2015 at 5:41 pm #2374 A ScientistKeymaster
A ScientistKeymasterI also agree. Even in cases where it is not super critical (say Coke vs Pepsi vs RC cola), different models will give a top score based on confidence. 3/4 models will say Pepsi is Pepsi, but 1/4 says it’s Coke. I guess as the one developing the model we should just reject the one that says Pepsi is Coke, but if you are developing a complex model with more than 3 samples, it might not be so simple.
And if you use the wrong model and scan somebody’s skin, it will tell you they are made of licorice…
Also, I’m developing models for candy (fat, sugar, etc) but when I tried to use the model on a butter curry chicken to impress my friends, it gave a value of -10% fat… so yeah, models need to be material-specific. Pretty sure butter chicken has more than -10% fat.
But overall, very impressed with the accuracy of application specific models!
 November 13, 2015 at 6:12 pm #2377Participant
November 13, 2015 at 6:12 pm #2377ParticipantA curry that subtracts 10% fat, sounds like there is a market there for that, do you have a recipe
November 15, 2015 at 3:56 am #2378 KhoaKeymaster
KhoaKeymasterJust a curious question. I wonder if narrowing the range of spectra can be really helpful to improve the confidence in your case?
November 15, 2015 at 9:02 am #2379rejsharpParticipantI asked this question of Consumer Physics.
Can we get a response saying that the scan does not match any others in the model?
Reply: The feature is under development.
No time scale given.
November 15, 2015 at 4:19 pm #2381ParticipantThanks rejsharp!,
So just to be clear, right now if I make an app to check if a mushroom is poisonous or edible, and my model have 20 types of mushrooms, 10 poisonous and 10 edibles, if the mushroom im scanning is not in my model, it MUST return as a match any of the ones that it has, and likely tell me that the one that Im scanning is not poisonous (even when it might be) without any way to tell me just “I dont have this one in my database”.
I cant think of any real life use for the scio if it MUST give you false positives of any element not in your model.
Can someone clarify how can you make any app until this is fixed?
Hopefully mi getting this wrong 😥 😥 😥
November 15, 2015 at 4:31 pm #2382ParticipantKoha,
The elements in my model are working very well, when I test the model it works recognizing the pill just right, the problem is when you bring another pill that is not in the model, instead of returning an error or empty, it return any of the elements in my model, and thus give you a false answer.
You can try with the hard cheese model that comes by default, just scan your skin ant it will tell you that you are cheese at x% fat.
November 15, 2015 at 6:39 pm #2385sakrelaasta
ParticipantOh, this is a huge problem!
It makes the qualitative analysis of anything impossible and dangerous.
It not acceptable to give you the “closest one” without even telling you “how close” it is.
The model is working fine, but it works fine because we check it with known pills. Knowing how it works, would anyone ever trust it to take an unknown pill?
November 15, 2015 at 6:49 pm #2386rejsharpParticipantAgreed! This is a critical feature that all “Recognition Apps” MUST have. As you guys say if the App estimates the wrong pill or the wrong mushroom it could be fatal.
If CP don’t post a reply, I will send a PM asking for re-assurance that this capability will be delivered soon.Roger
November 16, 2015 at 4:59 pm #2391eric_vanderwal@hotmail.com
ParticipantI must agree this is also a no-go for me. Without this feature, it is almost useless using the classification model. It needs an empty/ error/ % away from nearest sample response.
November 18, 2015 at 11:21 pm #2396ParticipantWill be great to hear from CP since it’s already a week since the post is online, Im waiting to see how to deal with this issue because without a fix I can’t imagine how to make anything useful with the Scio.
Any thoughts?, Am I the only one stuck?
November 20, 2015 at 5:26 pm #2399ParticipantEvery time I write in the forum I feel uneasy, because I haven’t yet received my scio and I don’t know if I haven’t understand something correctly or it is answered when you start working with it. BUT… curiosity! So:
-following our concerns about the lack of %error (or something like that) in qualitative analysis, I was wondering: At the quantitative apps is there anything more than the % concentration? Does the user know the limits (lower and higher) of the method, or the possible % error?
– If there isn’t anything extra information at the free apps, at least is there any statistical tool in the SDK?
In order to develop ANY serious analytical method we need data like loq, lod, standard deviation, correlation coefficients, or at least the repeatability of measurements. Is there any statistical information like that? Or can we extract the data to perform this analysis with other software?
The good thing is that at least all these are software problems, and it is possible to be solved (add more software tools in the SDK)
-
This reply was modified 9 years ago by
sakrelaasta.
-
This reply was modified 9 years ago by
-
AuthorPosts
{kind=link}
- You must be logged in to reply to this topic.